1. 이야기의 시작: RNN의 시대와 한계
컴퓨터가 사람처럼 말을 이해하려면 문장을 읽고 단어 사이의 관계를 파악해야 합니다. 처음엔 **RNN(Recurrent Neural Network)**이라는 기술이 주목받았어요. RNN은 문장을 순서대로 읽으며 기억을 쌓는 방식이었죠. 예를 들어, “나는 매일 아침 책을 읽는다”라는 문장을 “나는” → “매일” → “아침” → “책을” → “읽는다” 순으로 처리하며 문맥을 이해했어요.

하지만 RNN에는 큰 약점이 있었어요. 문장이 길어질수록 초반 단어를 잊어버리는 **장기 의존성 문제(Long-term Dependency Problem)**가 생겼죠. “나는 매일 아침 책을 읽고, 친구를 만나고, 커피를 마시고, 공원을 산책하는데, 사실 그건 다 어제 얘기다” 같은 문장에서 “어제”라는 핵심 정보를 끝까지 기억하기 힘들었어요. 게다가 RNN은 단어를 하나씩 처리하기 때문에 속도가 느렸고, 병렬 연산을 활용하기 어려웠어요.
연구자들은 이를 해결하려고 **LSTM(Long Short-Term Memory)**나 GRU(Gated Recurrent Unit) 같은 개선된 모델을 만들었지만, 근본적인 한계는 여전했어요. 그래서 새로운 영웅이 필요했죠.
2. Seq2Seq와 Attention의 등장 (2014년)
RNN의 한계를 넘기 위해 2014년, Sutskever 등이 발표한 논문 **"Sequence to Sequence Learning with Neural Networks"**에서 Seq2Seq 모델이 제안됐어요. Seq2Seq는 RNN(LSTM)을 사용해 입력 시퀀스를 압축(인코더)하고 출력 시퀀스를 생성(디코더)하는 구조로, 기계 번역에서 큰 성공을 거뒀죠.
같은 해, Bahdanau 등이 **"Neural Machine Translation by Jointly Learning to Align and Translate"**에서 Attention 메커니즘을 도입하며 Seq2Seq를 한 단계 발전시켰어요. Attention은 인코더의 모든 단어를 고정된 벡터로 압축하지 않고, 디코더가 출력할 때 입력의 중요한 부분에 “집중”하도록 했습니다. 예를 들어, “고양이가 쥐를 쫓는다”를 번역할 때 “고양이”와 “쫓는다”에 더 주의를 기울이는 식이었죠. 하지만 여전히 RNN 기반이라 병렬 처리는 불가능했어요.


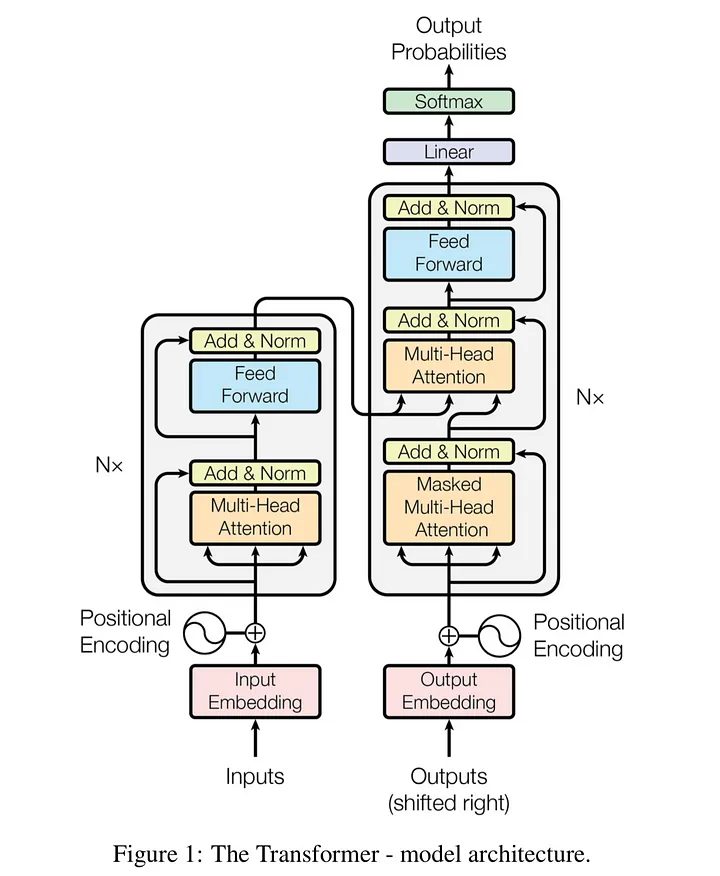
3. Transformer의 등장: Attention is All You Need (2017년)
2017년, “Attention is All You Need”라는 논문에서 Transformer가 세상에 나왔어요. Transformer는 RNN의 문제를 완전히 뒤바꾼 아이디어였죠. 문장을 하나씩 읽는 대신, 문장 전체를 한 번에 보고 단어 사이의 관계를 동시에 파악하는 방식이에요. 마치 우리가 책 한 페이지를 훑어보며 단어 간 연결을 직관적으로 이해하는 것과 비슷하죠.

Transformer는 **Attention(어텐션)**이라는 개념을 핵심으로 삼아, RNN의 순차적 처리와 장기 의존성 문제를 해결했어요. 이 덕분에 속도가 빨라졌고, 대규모 데이터를 다룰 수 있는 기반이 마련됐죠. 이게 바로 오늘날 ChatGPT나 BERT 같은 대형 언어 모델(LLM)의 뿌리가 된 기술이에요.
3.1 Attention 메커니즘
Transformer는 단어 사이의 관계를 파악할 때 “어느 단어가 중요한지”를 스스로 계산해요. 예를 들어, “고양이가 쥐를 쫓는다”에서 “고양이”와 “쫓는다”가 더 밀접하게 연결된다는 걸 알아내죠. 이건 RNN처럼 순서대로 기억을 쌓는 게 아니라, 문장 전체를 보고 중요도를 매기는 방식이에요.

3.2 병렬 처리
RNN은 단어를 하나씩 처리했지만, Transformer는 문장 전체를 동시에 볼 수 있어요. GPU 같은 병렬 연산 장치를 활용하면 훨씬 빠르게 학습하고 추론할 수 있죠. 이게 LLM 같은 대규모 모델을 만들 때 결정적인 장점이 됐어요.
3.3 셀프 어텐션(Self-Attention)
Transformer는 문장 안에서 단어들이 서로에게 얼마나 영향을 주는지 스스로 파악해요. “나는 어제 공원에서 책을 읽었다”에서 “어제”가 “읽었다”에 더 중요한 영향을 미친다는 걸 알아내는 식이에요.
3.4 인코더-디코더 구조
Transformer는 입력(예: 한국어 문장)을 이해하는 인코더와 출력(예: 영어 번역)을 만드는 디코더로 나뉘어요. 이 구조 덕분에 번역, 요약, 챗봇 같은 작업에서 강력한 성능을 발휘해요.
- Attention is all you need: https://arxiv.org/abs/1706.03762
- Neural Machine Translation by Jointly Learning to Align and Translate https://arxiv.org/abs/1409.0473
- https://nlpinkorean.github.io/illustrated-transformer/
- https://omicro03.medium.com/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-nlp-12%EC%9D%BC%EC%B0%A8-rnn-2-97f1650678b0
- https://karpathy.github.io/2015/05/21/rnn-effectiveness/
- https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
- https://wikidocs.net/31379